





OpenAI后谷歌又有大动作,DeepSeek“鲶鱼效应”搅动硅谷科技圈
- 房产
- 2025-02-06 17:40:04
- 1
尽管新模型表现优秀,谷歌在昨日晚间美股大跌7%,总市值减少超1800亿美元。
近半个月以来,DeepSeek在海外爆火,一度动摇了英伟达的“算力信仰”,来自硅谷的AI巨头们也普遍感受到压力,在近期纷纷发布新产品以捍卫优势。
继2月1日OpenAI发布推理模型 o3-mini后,北京时间2月6日,谷歌也高调更新了Gemini2.0全家桶,包括通用模型Gemini 2.0 Flash、谷歌最强的模型Gemini 2.0 Pro,以及性价比最高的模型Gemini 2.0 Flash-Lite。
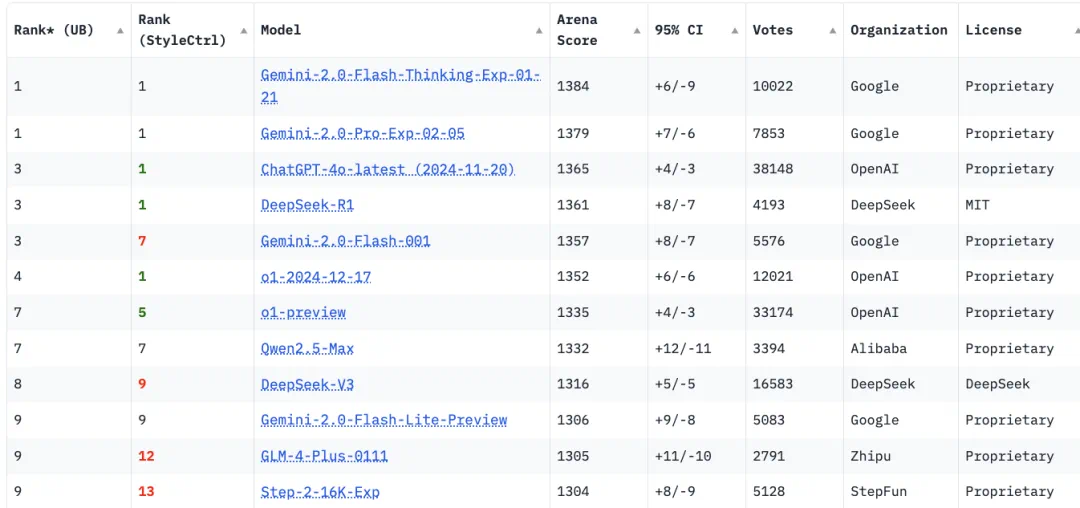
值得一提的是,谷歌这3款模型全部跻身大模型竞技场前10,Gemini 2.0 Pro 与四大模型并列第一,得分超过了GPT-4o和DeepSeek-R1,仅次于Gemini 2.0 Flash-Thinking。不过,DeepSeek-R1得分略微超过了Gemini 2.0 Flash。
尽管新模型表现优秀,谷歌在昨日晚间美股仍大跌超7%,几乎回吐今年以来全部涨幅,这也是该股近一年以来单日最大跌幅,总市值减少超1800亿美元。
昨日,谷歌首席执行官桑达尔・皮查伊(Sundar Pichai)在2024年第四季度财报中声明称,谷歌母公司 Alphabet 计划在2025年投入约750亿美元(当前约 5462.89 亿元人民币)用于资本支出,主要用于扩展人工智能产品和加码造数据中心。这个数字也远高于华尔街分析师预期的588亿美元。与此同时,谷歌云计算部门营收低于华尔街分析师预期,一定程度引发了投资者的担忧。
具体到这次发布,今日凌晨,皮查伊亲自站台,在X上连发三条推文官宣了Gemini 2.0系列更新。此次上新中,值得关注的模型主要是Gemini 2.0 Pro和Gemini 2.0 Flash-Lite。

Gemini 2.0 Pro是谷歌在编码和复杂指令任务中表现最好的模型,对世界知识的理解和推理能力方面也是谷歌旗下最强。根据官方数据,在谷歌旗下系列模型中,Gemini 2.0 Pro在13项评测中拿下11个第一。
同时,Gemini 2.0 Pro支持200万tokens上下文窗口,这也是谷歌所有模型中最大的上下文窗口,这使得模型能够全面分析和理解大量信息,并具备调用如谷歌搜索和代码执行等工具的能力。目前,作为实验性模型的Gemini 2.0 Pro已经在Google AI Studio和Vertex AI提供给开发者使用。
另一个值得注意的模型是Gemini 2.0 Flash-Lite,谷歌称这是目前为止性价比最高的模型,针对大规模文本输出进行了成本优化,同时在大模型竞技场总榜排在第9位。
根据官方说明,Gemini 2.0 Flash-Lite在速度和成本与Gemini 1.5 Flash持平,但大多数基准测试中,模型能力优于1.5 Flash。同时,模型具备100万tokens的上下文窗口,支持多模态输入。
Gemini 2.0 Flash-Lite最重要的特色是性价比和便宜。谷歌在博客中提到,如果让Gemini 2.0 Flash-Lite为4万张左右的不同照片,各自生成一句描述简介,按Google AI Studio定价,这个任务花费的总成本不超过1美元(约7.3元)。
市场认为,谷歌这一性价比模型的推出主要受到来自Deepseek模型的压力。
横向对比API价格,Gemini 2.0 Flash-Lite 的输入价格为0.075美元/每100万Tokens;在击中缓存的情况下,价格将下降至0.01875美元/每100万Tokens。同样的条件下,OpenAI的性价比模型(gpt-4o-mini)最低只能做到0.075美元/每100万Tokens。
目前性价比更突出、性能更强的DeepSeek-V3模型,在击中缓存的情况只需要0.014美元/每100万Tokens。不过DeepSeek已经宣布,从2月8日开始,价格会翻5倍至0.07美元/每100万Tokens。
此外谷歌面向用户最为通用的模型是新版Gemini 2.0 Flash,去年2024年谷歌I/O大会上,Gemini 2.0 Flash实验版首次亮相,现在,Gemini 2.0 Flash已经集成到谷歌的AI产品中,人人可用。
谷歌DeepMind的CTO在博客中表示,Gemini 2.0 Flash提供了全面的功能,适合大规模处理高容量、高频率任务。并且具备100万tokens长文本能力,支持对海量信息进行多模态推理。
近日硅谷AI巨头都感受到了来自DeepSeek的压力。前几日,OpenAI刚发布新一代推理模型o3-mini,卷入价格战。OpenAI在提供越来越低的API调用价格,据官方介绍,自GPT-4推出以来,每个token的定价下降了95%。
在近期的问答中OpenAICEO奥尔特曼被问及DeepSeek时,肯定了DeepSeek有非常好的模型,同时表示OpenAI将生产更好的模型,“但与往年相比,我们的领先优势将更小。”
在此次谷歌财报电话会上,皮查伊也被问及DeepSeek,他回复称,“他们有一支了不起的团队,我认为他们做得非常、非常好。”皮查伊补充称,与DeepSeek的V3和R1模型相比,谷歌旗下Gemini的Flash轻量型号也很有效率。
对于DeepSeek- R1的深层影响,皮查伊表示,全球范围内更便宜的AI的兴起只会增加这项技术的采用率,谷歌将由于其数十亿用户规模而受益。
尽管DeepSeek的低成本、高性能给海外带来滔天巨浪,但几大科技巨头在近期的财报中都释放了加码资本支出的信号,继续“猛踩油门”。
2025 年,谷歌的资本支出将高达 750 亿美元,高于去年的525亿美元,比市场预期高出32%。DA Davidson分析师 Gil Luria 表示,如果这是 Alphabet的新趋势,那么投资者应该感到担忧。不过皮查伊表示,支出目标旨在加快进步。
与此同时,Meta和微软在1月底的财报电话会议上也都加倍了支出计划,并未因DeepSeek的崛起而受到影响。高管认为,AI领域的巨额投入是必要的,随着时间的推移,获得数据中心和先进芯片的使用权将成为一项关键优势。
具体来看,2025年Meta将投入600亿至650亿美元用于AI开发,CEO扎克伯格认为,随着时间的推移,这些投资将成为公司的战略优势。微软也重申2025年资本支出将持续增加,预计投资800亿美元建立AI数据中心。
摩根士丹利在去年11月发布的报告显示,亚马逊、Google、Meta和微软2025年的资本支出合计将达到3000亿美元左右,2026年将进一步增长至3365亿美元。
相关文章
热门文章

大摩将2025年视为晶圆厂设备“过渡期” 下调应用材料评级
2024-12-05
英伟达的竞品,真的出现了!
2024-12-07
跨年行情即将开启!机构:这些策略和板块值得关注
2024-12-08
第六届新浪财经金麒麟食品饮料行业最佳分析师:第一名华创证券欧阳予研究团队
2024-12-05
凯里东南村镇银行被罚30万元:未严格执行风险管理及内控制度严重违反审慎经营规则
2024-11-21
一则传闻吹出三个涨停板,紧急回应:不存在!
2024-11-21
中通快递盘前涨近3% 第三季营收破百亿 同比增长17.6%
2024-11-21
佩斯科:2024年债务市场发行量将创下历史新高
2024-11-21
有话要说...